Difference between revisions of "TaskHtmPrimary"
(Automated page entry using MWPush.pl) |
(No difference)
|
Revision as of 01:30, 16 June 2015
Implement working model of HTM
@@Home -> ReleasePlanning -> TaskHtmPrimary
Contents
What
- discover features potentially supported by HTM
- specify interface for HTM in current framework
- integrate any existing Open Source implementation into framework
- choose sample task: computer vision or narrative understanding from real chat
- make working demo implementation for sample task
How
- Currently openCV library from INTEL is being researched on to see if we can integrate it into our HTM module
Architecture
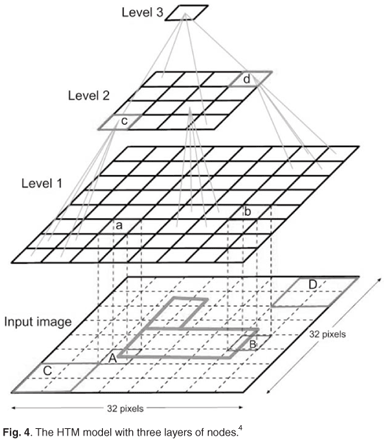
- libbn will be developed based on the architecture shown above.
Implementation
- libbn will be a generic library that can be integrated into any module using a adaptation layer.
- For computer vision this adaptation layer will be implemented using openCV library that will get the image data and feed it to the HTM network for creating ahuman memory.
Mathematical Model proposed by researchers at MIT for Human Brain
The model was designed to reflect neurological evidence that in the primate brain, object identification -- deciding what an object is -- and object location -- deciding where it is -- are handled separately. Although what and where are processed in two separate parts of the brain, they are integrated during perception to analyze the image.
The mechanism of integration, the researchers argue, is attention. According to their model, when the brain is confronted by a scene containing a number of different objects, it can't keep track of all of them at once. So instead it creates a rough map of the scene that simply identifies some regions as being more visually interesting than others. If it's then called upon to determine whether the scene contains an object of a particular type, it begins by searching -- turning its attention toward -- the regions of greatest interest.
The software's analysis of an image begins with the identification of interesting features -- rudimentary shapes common to a wide variety of images. It then creates a map that depicts which features are found in which parts of the image. But thereafter, shape information and location information are processed separately, as they are in the brain.
The software creates a list of all the interesting features in the feature map, and from that, it creates another list, of all the objects that contain those features. But it doesn't record any information about where or how frequently the features occur.
At the same time, it creates a spatial map of the image that indicates where interesting features are to be found, but not what sorts of features they are.
It does, however, interpret the "interestingness" of the features probabilistically. If a feature occurs more than once, its interestingness is spread out across all the locations at which it occurs. If another feature occurs at only one location, its interestingness is concentrated at that one location.
Mathematically, this is a natural consequence of separating information about objects' identity and location and interpreting the results probabilistically. But it ends up predicting another aspect of human perception, a phenomenon called "pop out." A human subject presented with an image of, say, one square and one star will attend to both objects about equally. But a human subject presented an image of one square and a dozen stars will tend to focus on the square.
Like a human asked to perform a visual-perception task, the software can adjust its object and location models on the fly. If the software is asked to identify only the objects at a particular location in the image, it will cross off its list of possible objects any that don't contain the features found at that location.
By the same token, if it's asked to search the image for a particular kind of object, the interestingness of features not found in that object will go to zero, and the interestingness of features found in the object will increase proportionally. This is what allows the system to predict the eye movements of humans viewing a digital image, but it's also the aspect of the system that could aid the design of computer object-recognition systems. A typical object-recognition system, when asked to search an image for multiple types of objects, will search through the entire image looking for features characteristic of the first object, then search through the entire image looking for features characteristic of the second object, and so on. A system like Poggio and Chikkerur's, however, could limit successive searches to just those regions of the image that are likely to have features of interest.